Pdf to Excel with C#
Step by step to convert your PDF to Excel in C#
Nov 8, 2023 | Read time 9 minutes
📗 Table of contents
Introduction
A recent project that I was involved in had a task to extract data from a PDF document using C#.
After we have extracted the table data, we can then put it into a Excel sheet of place it in a database table.
In this post, I will go over how to export data from a PDF and then save it to Excel.
We will be using PdfDodo’s API to do this.
Step 1: Get Pdfdodo API Key
PdfDodo uses a API keys to allow you to access the API. You can get your API key by going to the “Settings” section.
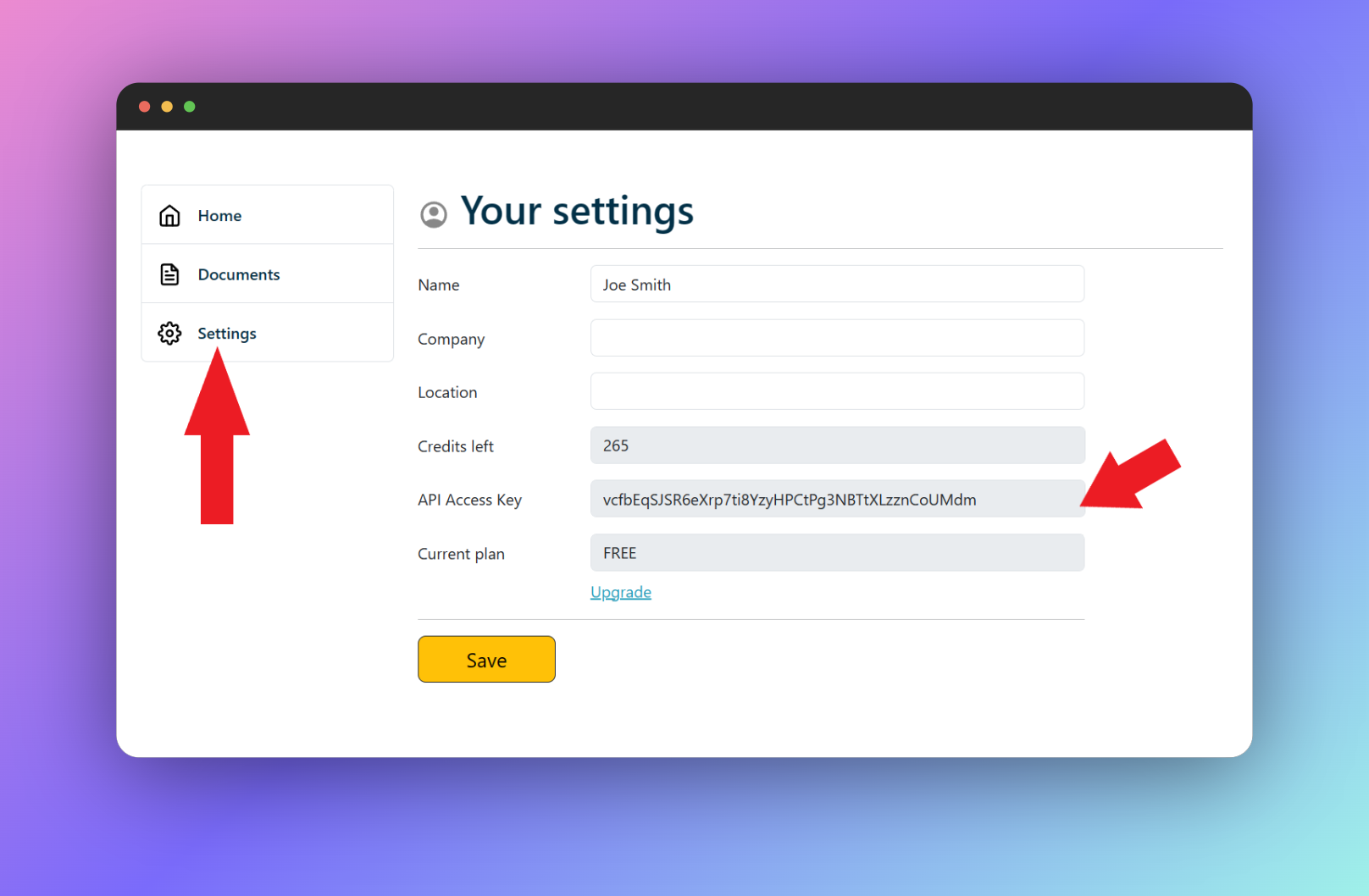
After retrieving your API key, you can pass the token to the API in the HTTP Authorization Header using X-API-KEY.
X-API-KEY: <apikey>Step 2: Upload a PDF file
The next step after we have successfully grabbed our API key, we can upload our document and then call the analyze endpoint to get the data.
Make sure to add X-API-KEY in the Authorization Header.
To upload our PDF file, we can do this in C# as follows and call the api/uploadfile endpoint.
using System;
using System.Net.Http;
using System.Threading.Tasks;
using System.IO;
class Program
{
static async Task Main()
{
var apiKey = "YOUR_API_KEY"; // Replace with your actual API key
var filePath = "/path/to/your/file.pdf"; // Replace with the path to your PDF file
var url = "https://app.pdfdodo.com/api/uploadfile"; // The API endpoint
using (var httpClient = new HttpClient())
{
using (var form = new MultipartFormDataContent())
{
httpClient.DefaultRequestHeaders.Add("x-api-key", apiKey);
// Assuming the file is on the disk, and we can open a read stream
using (var fs = File.OpenRead(filePath))
{
using (var streamContent = new StreamContent(fs))
{
using (var fileContent = new ByteArrayContent(await streamContent.ReadAsByteArrayAsync()))
{
fileContent.Headers.ContentType = new System.Net.Http.Headers.MediaTypeHeaderValue("multipart/form-data");
// "file" is the name of the parameter for the file upload
form.Add(fileContent, "file", Path.GetFileName(filePath));
// Post the form to the URL
HttpResponseMessage response = await httpClient.PostAsync(url, form);
if (response.IsSuccessStatusCode)
{
Console.WriteLine("File uploaded successfully!");
}
else
{
Console.WriteLine("File upload failed!");
}
// Read the response content and output it to the console
string responseContent = await response.Content.ReadAsStringAsync();
Console.WriteLine(responseContent);
}
}
}
}
}
}
}Keep note of the documentId.
Step 3: Call the analyze endpoint
The next step is to do a GET request to the analyze endpoint, /api/analyze, to get the document data.
For example, lets say our document id is 123e4567-e89b-12d3-a456-426614174000, we can do the following Python code to analyze and get the document data:
using System;
using System.Net.Http;
using System.Threading.Tasks;
class Program
{
static async Task Main()
{
// Replace YOUR_API_KEY_HERE with your actual API key
string apiKey = "YOUR_API_KEY_HERE";
string documentId = "123e4567-e89b-12d3-a456-426614174000";
string baseUri = "https://app.pdfdodo.com/api/analyze";
string uri = $"{baseUri}?documentid={documentId}/results";
using (var httpClient = new HttpClient())
{
// Add the API key to the request headers
httpClient.DefaultRequestHeaders.Add("x-api-key", apiKey);
httpClient.DefaultRequestHeaders.Accept.Add(new System.Net.Http.Headers.MediaTypeWithQualityHeaderValue("application/json"));
// Send the GET request
var response = await httpClient.GetAsync(uri);
// Ensure we get a success status code
response.EnsureSuccessStatusCode();
// Read the response content
var responseContent = await response.Content.ReadAsStringAsync();
Console.WriteLine(responseContent);
}
}
}This will give you a JSON response of the data in your PDF:
{
"tables": [
{
"title": "The title of your table",
"tableId": "a0f229f6-ade7-4637-bbff-e31fbbd64ec5",
"pageNumber": 1,
"rows": [
[
"0",
"Money In ",
"$1,880.00 "
],
[
"1",
"Money Out ",
"$150.25 "
],
[
"2",
"You Received ",
"$1,729.75 "
]
],
"left": 0.6953286,
"top": 0.2655254,
"width": 0.2580709,
"height": 0.11655326,
"mergedTables": []
}
]
}We can then use this JSON response to save it to a database.
Step 4: Save JSON as Excel
The last step is to take the above JSON response and save it as a excel spreadsheet.
In my case, I had to save it as a excel file. We can use Newtonsoft.Json to parse the JSON and the “Microsoft Excel Object Library” to create Excel files.
To work with the Microsoft Excel Object Library, also known as Microsoft.Office.Interop.Excel, you’ll need to add a reference to the library in your project
using Microsoft.Office.Interop.Excel;
using Newtonsoft.Json.Linq;
using _Excel = Microsoft.Office.Interop.Excel;
public void JsonToExcel(string jsonString)
{
// Parse the JSON string
JObject jsonObject = JObject.Parse(jsonString);
// Start Excel and get Application object.
var excelApp = new _Excel.Application();
excelApp.Visible = true; // You can set this to false if you don't want the Excel window to be visible
// Create a new, empty workbook and add a worksheet.
_Excel.Workbook workbook = excelApp.Workbooks.Add(Type.Missing);
_Excel.Worksheet worksheet = (_Excel.Worksheet)workbook.Worksheets[1];
// Get the table rows from JSON
JArray rows = (JArray)jsonObject["tables"][0]["rows"];
// Iterate over each row and column to write the data to the sheet
for (int i = 0; i < rows.Count; i++)
{
JArray row = (JArray)rows[i];
for (int j = 0; j < row.Count; j++)
{
// Excel is 1-indexed
worksheet.Cells[i + 1, j + 1] = row[j];
}
}
// Save the workbook and Quit Excel
workbook.SaveAs(@"C:\path\to\your\spreadsheet.xlsx");
workbook.Close();
excelApp.Quit();
}Now this option is free and does not require external libraries to work with Excel.
The main limitation with the above is that you will need Office (Excel, Word, etc) to be installed on the machine that is running the above code.
If you do not want the interop dependency (installing Office on your machine), another option is the OpenXML SDK library:
https://github.com/dotnet/Open-XML-SDK
This just exists as a DLL reference and you can install it through Nuget. https://www.nuget.org/packages/DocumentFormat.OpenXml
using System;
using System.Collections.Generic;
using DocumentFormat.OpenXml;
using DocumentFormat.OpenXml.Packaging;
using DocumentFormat.OpenXml.Spreadsheet;
using Newtonsoft.Json;
class Program
{
static void Main(string[] args)
{
// Your JSON string
string jsonString = @"{
'tables': [
{
'title': 'The title of your table',
'tableId': 'a0f229f6-ade7-4637-bbff-e31fbbd64ec5',
'pageNumber': 1,
'rows': [
['0', 'Money In', '$1,880.00'],
['1', 'Money Out', '$150.25'],
['2', 'You Received', '$1,729.75']
]
}
]
}";
// Deserialize the JSON string into a C# object
var response = JsonConvert.DeserializeObject<JsonResponse>(jsonString);
// Create a new Excel file
string filePath = "output.xlsx";
using (SpreadsheetDocument spreadsheetDocument = SpreadsheetDocument.Create(filePath, SpreadsheetDocumentType.Workbook))
{
// Add a WorkbookPart to the document.
WorkbookPart workbookpart = spreadsheetDocument.AddWorkbookPart();
workbookpart.Workbook = new Workbook();
// Add a WorksheetPart to the WorkbookPart.
WorksheetPart worksheetPart = workbookpart.AddNewPart<WorksheetPart>();
worksheetPart.Worksheet = new Worksheet(new SheetData());
// Add Sheets to the Workbook.
Sheets sheets = spreadsheetDocument.WorkbookPart.Workbook.AppendChild(new Sheets());
// Append a new worksheet and associate it with the workbook.
Sheet sheet = new Sheet()
{
Id = spreadsheetDocument.WorkbookPart.GetIdOfPart(worksheetPart),
SheetId = 1,
Name = response.Tables[0].Title
};
sheets.Append(sheet);
SheetData sheetData = worksheetPart.Worksheet.GetFirstChild<SheetData>();
// Add header row to the Excel file
Row headerRow = new Row();
headerRow.Append(
new Cell() { CellValue = new CellValue("Id"), DataType = CellValues.String },
new Cell() { CellValue = new CellValue("Description"), DataType = CellValues.String },
new Cell() { CellValue = new CellValue("Amount"), DataType = CellValues.String }
);
sheetData.AppendChild(headerRow);
// Add the data rows to the Excel file
foreach (var rowData in response.Tables[0].Rows)
{
Row newRow = new Row();
foreach (string cellValue in rowData)
{
newRow.Append(new Cell() { CellValue = new CellValue(cellValue), DataType = CellValues.String });
}
sheetData.AppendChild(newRow);
}
workbookpart.Workbook.Save();
}
Console.WriteLine("Excel file created successfully!");
}
}
// Define classes to match the JSON structure
public class JsonResponse
{
public List<Table> Tables { get; set; }
}
public class Table
{
public string Title { get; set; }
public List<List<string>> Rows { get; set; }
}Final thoughts
Overall to convert PDF to Excel, we can do the following steps:
- Extract the data from the PDF using PdfDodo API
- Parse the JSON response using Newtonsoft.Json library
- Create the Excel file using Microsoft Excel Object Library.
If you do not want to have interop dependencies, then consider using the Open XML SDK.
👋 About the Author
G'day! I am Ken Ito a software engineer based in Australia. I have worked as a software engineer for more than 10 years ranging from roles such as tech lead, data analyst to individual contributor. I have experience in creating code (python, javascript) to extract data from PDFs for ETL and financial statement analysis for accounting purposes.
During those years, I have worked for Government departments, companies like NTT (Nippon Telegraph and Telephone), Bupa and not-for-profit organizations.
3 Ways to Convert Pdf to Excel Without Losing Formatting
Sep 21, 2023Step by Step to convert your scanned PDFs to Excel without losing formatting.
How to Convert PDF to CSV with python
Oct 26, 2023Step by step to convert your scanned PDF bank statement to Excel format using Python
Extract Tables from Pdf using Python
Oct 24, 2023Guide to get tables from PDFs using Python